At Localytics, data is central to our mission. One of our core principles is to "lead with data." When I envision that, I often think of an analyst using graphs to make a case for a business decision, or a principal engineer using benchmarks to advocate for a particular technology, or an ops engineer's alarm going off, showing a warning about a production system. But when I think more carefully about it, these things are the results, or at least the intermediate products, of data-driven decision-making. In this post, I will focus on the earlier steps of the process, and introduce exploranda, a tool for enabling those first steps.
The first step in making decisions based on data is letting something catch your attention. Obvious things will catch your attention sometimes. S3 will go down. Third-party APIs will go down. Sometimes (rarely, of course!) code that you yourself wrote will break. For most of the obvious things there will be a known response pattern: investigate the outage, do whatever is possible to mitigate or undo its effects, conduct a postmortem to address any structural or longer-term issues uncovered by the event, and find a place for longer-term actions in the backlog. This pattern is so effective and well-established that we can use tools to preempt it sometimes: automated monitoring systems tell us about worrying trends in the steady-state of our deployed infrastructure, CI keeps forseeable bugs out of production, CD automates quick rollbacks or forward-fixes.
In other cases, the thing that catches your attention will not be obvious, or the cause of an obvious thing will be difficult to discover. Maybe a service "feels slow," even though all the metrics say it should be fine. Maybe transient errors keep occurring in a particular cluster but don't leave evidence in the logs. Maybe you're switching from a familiar technology with well-understood properties to a newer one that isn't as well-known but might offer advantages. These are examples of data exploration tasks that call for curiosity, openmindedness, and flexibility. They are characterized by "unknown unknowns" and open-ended problem statements.
Unfortunately, the tools that work so well for preempting forseeable problems are not as well-suited to investigating unforseen problems or answering arbitrary questions. Adding a suddenly-important metric to a monitoring system might require a redeployment at a time when a system is already in a bad state. When evaluating a new service, standing up a whole monitoring solution or integrating the new service with an existing monitoring solution might not be an efficient use of time. When investigating a transient problem, the first few things you choose to measure may end up being totally irrelevant. The security requirements of a critical system might put it beyond the reach of third-party tools, but it might be accessible from within a particular network.
Exploranda is a tool I built to help with these use-cases in my daily work. It is a Node.js package that enables data exploration by breaking it down into a three-step pipeline: getting raw data from arbitrary sources, transforming the data to highlight features of interest, and displaying the data in a useful way. Exploranda allows me to build complicated models of Localytics infrastructure from simple, mostly-declarative objects.
For instance, we have an Elasticsearch cluster running in AWS ECS. The individual nodes are containers running on container instances. The containers write to an EBS volume mounted on the container instance that isn't the root volume. If I want to see the IO stats for the container with the highest disk usage, this is the process I would have to use:
- Log in to an Elasticsearch monitoring system, or use the Elasticsearch API, to determine the IP
of the node with the highest disk usage. - Log in to AWS, click to EC2, search by IP for the instance with the same IP as the Elasticsearch node.
- Click on the instance, scroll down through the tiny data pane to the section where it lists the
mounted volumes. - Find the volume that seems to be the data volume, either by remembering the mount point or comparing
the properties of the other volumes. Click on it. - On the EBS page, click on the 'Cloudwatch Metrics" tab in the tiny data pane. Look at the IO stats.
By the time I get to the information I was after, I've lost most of the context. I don't just mean that I've lost my train of thought, though I probably have--I also mean that the page with the IO metrics on it has no other contextual information relevant to my question. It doesn't have the IP of the Elasticsearch node. It doesn't show the disk usage. And if I want to compare the IO of this node to the IO of the others, that process is a multiple of the complexity of this one.
Here is how that process is represented using exploranda:
const _ = require('lodash');
const exploranda = require('exploranda');
const {ebsMetricsBuilder} = exploranda.dataSources.AWS.ebs;
const {filteredInstancesBuilder} = exploranda.dataSources.AWS.ec2;
const es = exploranda.dataSources.elasticsearch;
const awsConfig = {region: 'us-east-1'};
const esHost = 'http://my.es.host:9200';
// First we specify the information we need
const dependencies = {
nodeStats: {
// this will provide the results of calling the
// /_nodes/stats endpoint on elasticsearch
accessSchema: es.nodeStats,
params: {
esHost: {value: esHost}
},
},
nodeInstances: filteredInstancesBuilder(awsConfig, {
// to get the instances from AWS,
// we can use the IPs we got from the elasticsearch,
// so we specify that the source of data for this parameter
// is the `nodeStats` dependency, and exploranda will figure
// out the correct order to get things
source: 'nodeStats',
// this function produces the value that will be used as the
// Filters parameter in the AWS api call. We're filtering
// for instances with the IPs of the ES nodes. Exploranda
// knows the AWS API well enough that it will get all of the results
// for this filter, even if it needs to make multiple calls.
formatter: (nodeStats) => [{
Name: 'private-ip-address',
Values: _.map(nodeStats.nodes, 'host')
}]
}),
nodeVolumeReadOps: ebsMetricsBuilder(awsConfig,
{value: 'VolumeReadOps'},
// When we know the literal value of a parameter beforehand
// (for instance, we know we want the Sum statistic of the read
// ops) we specify it as an object with a `value` key, instead
// of a `source` and `formatter`
{value: ['Sum']},
// Now we use the `nodeInstances` dependency, which is
// an array of instance objects from AWS, to ask for
// IO metrics for the volumes listed as mounted on /dev/sdb
// for each of the instances.
{source: 'nodeInstances', formatter: (instances) => {
return _.map(instances, (i) => {
return [{
Name: 'VolumeId',
Value: _.find(
i.BlockDeviceMappings,
(bdm) => bdm.DeviceName === '/dev/sdb').Ebs.VolumeId
}];
});
}}
),
nodeVolumeWriteOps: ebsMetricsBuilder(awsConfig,
{value: 'VolumeWriteOps'},
{value: ['Sum']},
{source: 'nodeInstances', formatter: (instances) => {
return _.map(instances, (i) => {
return [{
Name: 'VolumeId',
Value: _.find(
i.BlockDeviceMappings,
(bdm) => bdm.DeviceName === '/dev/sdb').Ebs.VolumeId
}];
});
}}
)
};
const ipColors = {};
function getIpColor(ip) {
if (!ipColors[ip]) {
ipColors[ip] = [
Math.random() * 255,
Math.random() * 255,
Math.random() * 255
];
}
return ipColors[ip];
}
// After the dependencies, we transform it based on our
// intended outputs.
const transformation = {
'ElasticSearch Node Write Ops': {
type: 'CUSTOM',
// Like the parameters in the `dependencies` stage, here we
// specify the dependencies that this output requires, and they are
// passed to a tableBuilder function.
source: ['nodeInstances', 'nodeVolumeWriteOps'],
// this builds a table of values that can be passed into a
// blessed-contrib (yaronn/blessed-contrib) graph.
tableBuilder: ({nodeInstances, nodeVolumeWriteOps}) => {
const ips = _.map(nodeInstances, 'PrivateIpAddress');
return _.map(
_.zip(ips, nodeVolumeWriteOps),
([ip, metricArray]) => {
metricArray = _.sortBy(metricArray, 'Timestamp');
return {
title: ip,
// Exploranda is structured so that you don't need to worry
// about when things get executed, but it doesn't restrict
// you from doing synchronous things "on the side." Note that the
// `getIpColor` function selects a color the first time you pass it an IP,
// and then always returns the same color for that IP. This lets you
// have consistent coloring for similar data across all of your graphs,
// without needing to know too much beforehand.
style: {line: getIpColor(ip)},
x: _.map(metricArray, (point) => point.Timestamp.getMinutes().toString()),
y: _.map(metricArray, 'Sum')
};
}
);
}
},
'ElasticSearch Node Read Ops': {
type: 'CUSTOM',
source: ['nodeInstances', 'nodeVolumeReadOps'],
tableBuilder: ({nodeInstances, nodeVolumeReadOps}) => {
const ips = _.map(nodeInstances, 'PrivateIpAddress');
return _.map(
_.zip(ips, nodeVolumeReadOps),
([ip, metricArray]) => {
metricArray = _.sortBy(metricArray, 'Timestamp');
return {
title: ip,
style: {line: getIpColor(ip)},
x: _.map(metricArray, (point) => point.Timestamp.getMinutes().toString()),
y: _.map(metricArray, 'Sum')
};
}
);
}
}
};
// After specifying the dependencies and transformation, we
// specify how the data should be displayed.
const display = {
// This section will be rendered as line charts. Other
// visualizations and text elements are also available
lines: {
// the objects in the display stage specify how to render the data
// from the section of the `transformation` stage with the same key.
'ElasticSearch Node Write Ops': {
// These objects specify size, position, and sometimes
// other style data for the graphs based on a 12x12 grid
column: 0,
row: 0,
rowSpan: 6,
columnSpan: 12
},
'ElasticSearch Node Read Ops': {
column: 0,
row: 6,
rowSpan: 6,
columnSpan: 12
}
}
};
const reporter = new exploranda.Reporter();
reporter.setSchemas({
// to debug, you can comment out either the `display`
// or the `transformation` and `display` elements
// and the output will be the raw JSON of the last stage
// to run.
dependencies,
transformation,
display
});
reporter.execute();
And when I run that, this is what I see, right in the console:
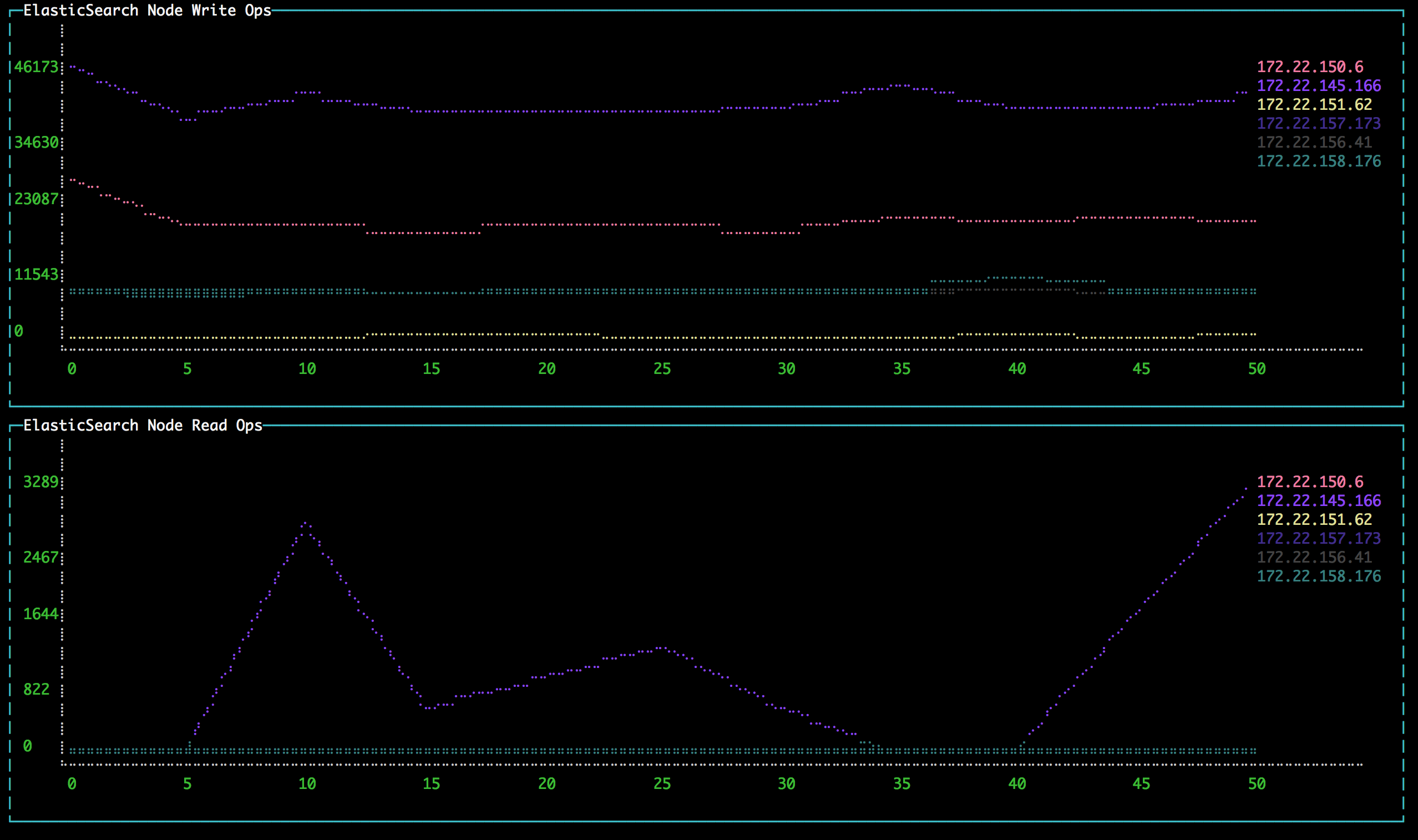
All of the IO stats for all of the instances, identified by their IP addresses, updated in real time, without making a single infrastructure change. Conversely, adding this metric to an existing system would be a much larger effort: because the exact volumes we care about are only identifiable by tracing back through the chain of relationships to the Elasticsearch nodes (or at least their container instances), we would probably need to deploy a special process, like a lambda or an ECS task, to get the data and post it to the monitoring system. Or maybe we could tag the volumes as belonging to Elasticsearch...and set up a Cloudwatch dashboard for them...but we'd have to tag them with the correct IPs as well...Is there a convenient way to fit that into the deployment system? Should we have a design discussion?
This kind of friction is deadly to the practice of data exploration, because it raises the cost of asking questions and discourages you from pursuing data unless you already know that it will be relevant. In fact, the measure of success of data exploration should not only be "Did I learn about the thing that caught my attention in the first place?" Instead, it should also include "Did I find something surprising that I wasn't looking for, but which turned out to be important?" With incredible regularity, I find that using Exploranda to observe the systems I work on uncovers unexpected and interesting things without requiring a lot of effort.
Of course, this is not a replacement for other monitoring systems. It polls for data and updates in real time without storing historical data. It complements structural, always-on monitoring systems in two ways: first, it enables easy, flexible data gathering for the times when you just want to answer one question or examine something without a lot of investment. Second, it lets you test out metrics that would be expensive to integrate into an existing system, giving you a cheap way to decide if they would be worth the effort.
Finally, Exploranda's transformation and display steps are optional, making it a convenient adapter for any tasks that require AWS or other data. Part of my motivation was the simple fact that traversing the graph of AWS services, from task definition to container instance to ec2 instance to AMI name, commonly results in deeply-nested code that is difficult to reuse, maintain, and extend. Exploranda's use of consistent, documented patterns is intended to alleviate some of that pain, and make it easier to integrate data from multiple sources. Right now it is possible to get information from AWS APIs and HTTP(S) requests; shell and SSH commands are areas of interest I hope to address in the near future.
Exploranda is still in beta: the major version is 0, and there may be breaking changes before v1 is released. It's available on github and via npm install exploranda. Feedback is welcome. Exploranda depends on the excellent blessed and blessed-contrib libraries for console display, the awe-inspiring async and lodash libraries for functional primitives, and request along with the aws-sdk to get dependencies. Its development dependencies are minimist for argument parsing in the examples, and jasmine and rewire for tests.