At Localytics, we run a massive Vertica cluster in Amazon as a core component of our Data Platform. Our business is scaling at a fast pace, and our platform infrastructure (including Vertica) must scale with it. On the Platform team, we are constantly looking for ways to keep up with growth.
This post explores the journey to arrive at our current configuration of r3.4xlarge memory-optimized instances backed by Amazon Elastic Block Store (EBS).
Until earlier this year, we ran our cluster on hs1.8xlarge storage-optimized instances which feature up to 48 terabytes of direct-attach storage. Learn more about Amazon EC2 instance types (like hs1.8xlarge and r3.4xlarge)
We decided to switch to EBS for the following reasons:
- Effortless backups using EBS snapshots
- Spin up clusters directly from EBS snapshots
- Spin up clusters with production data for performance testing
- Reduce operational overhead
- Take advantage of instances with better hardware characteristics
We made our decision just as AWS released their shiny new D2 instances fleet. We stuck with our plan to run EBS-backed for the operational benefits.
Here are the challenges we faced during the migration, and how we iterated on configurations.
Challenge #1: The Case of the Wrong Benchmarks
When we stood up a r3.8xlarge cluster backed by EBS it measured up very well against the hs1.8xlarge cluster, it had on a per-node basis double the compute power: 16 vs 8 cores at 2.5 ghz vs 2.0 ghz, more than double the memory: 244 GB vs 117 GB and it was running on a newer OS/kernel: Centos 6 w/ 2.6.32 vs Centos 5 w/ 2.6.18.
Compared to the HS1s, though, we would have less i/o bandwidth available to us (800 MB/s vs 2400 MB/s) but we have historically not been bound on i/o. Additionally, in single-user query benchmarks it ran 2x as fast in comparison to the hs1.8xlarge cluster.
When we re-directed a portion of our traffic to this cluster, Vertica promptly suffered performance degradation. However, according to all of our system monitoring tools -- the cluster was not stressed.
We created a new benchmark tool that could simulate production load traffic on a different cluster. We did this simply by replaying Vertica query history the same exact way it happened in Production. This new benchmark allowed us to identify the root cause of the problem.
Here are the results of our new benchmark tool:
| Aggregate Runtime (seconds) | Timeout Rate (%) | Configuration |
|---|---|---|
| 893 | 0.0% | hs1.8xlarge, 2.6 kernel, instance storage, 10 Gb eth |
| 9426 | 74.5% | r3.8xlarge, 2.6 kernel, EBS magnetic, 10 Gb eth |
We now clearly saw that the new cluster had major issues. Vertica could not clear the queries fast enough and as more came in, it created a traffic jam which caused Vertica to start queueing and eventually timing out queries due to our timeout settings-- leading to a high aggregate runtime and error rate.
Challenge #2: 2.6 kernel and CPU spinlock
We iterated on different changes we can make in our cluster and found that the majority of the performance problems were due to using the 2.6 kernel running into CPU spinlock, which is a known problem in virtualized environments. What this means is that too much time is spent by the CPUs in coordinating between themselves. Also remember that the hs1.8xlarge cluster had half the number of cores.
We upgraded our kernel to 3.10 and found these new results of our benchmark:
| Aggregate Runtime (seconds) | Timeout Rate (%) | Configuration |
|---|---|---|
| 893 | 0.0% | hs1.8xlarge, 2.6 kernel, instance storage, 10 Gb eth |
| 9426 | 74.5% | r3.8xlarge, 2.6 kernel, EBS magnetic, 10 Gb eth |
| 898 | 0.0% | r3.8xlarge, 3.10 kernel, EBS magnetic, 10 Gb eth |
Challenge #3: Smaller is Better
Despite the 3.10 kernel being better about spinlock, we still observed some spinlock. We decided to try running on r3.4xlarge boxes since there would be less CPUs to coordinate and found success:
| Aggregate Runtime (seconds) | Timeout Rate (%) | Configuration |
|---|---|---|
| 893 | 0.0% | hs1.8xlarge, 2.6 kernel, instance storage, 10 Gb eth |
| 9426 | 74.5% | r3.8xlarge, 2.6 kernel, EBS magnetic, 10 Gb eth |
| 898 | 0.0% | r3.8xlarge, 3.10 kernel, EBS magnetic, 10 Gb eth |
| 414 | 0.0% | r3.4xlarge, 3.10 kernel, EBS magnetic, 2.0Gb EBS optimized eth |
We did not for our use case see an issue with having 2.0Gb/s dedicated for EBS traffic vs. a general purpose 10Gb/s on the 8x boxes.
Challenge #4: Scaling up
We cashed in on our 2x performance gains with the above configuration and were happy for a while. But, our business is growing so fast and we are scaling at a rate where some of our wins were erased and we needed to look for the next edge. At Localytics, we cannot be satisfied with our wins for too long because each day brings several terabytes of data as well as new clients using our product.
Challenge #5: Vertica vs. the Kernel
Up until this point we had been running Vertica 6.1, so we looked for more performance gains in Vertica 7.1.2. After we initially upgraded, the good news was that our performance had doubled again, the bad news was that nodes were randomly dropping due to a memory page fault error.
After this, we tested many versions of the kernel with Vertica 7, and found that kernel 4.1.8 worked well.
Below is a response time graph of when we turned Vertica 7:
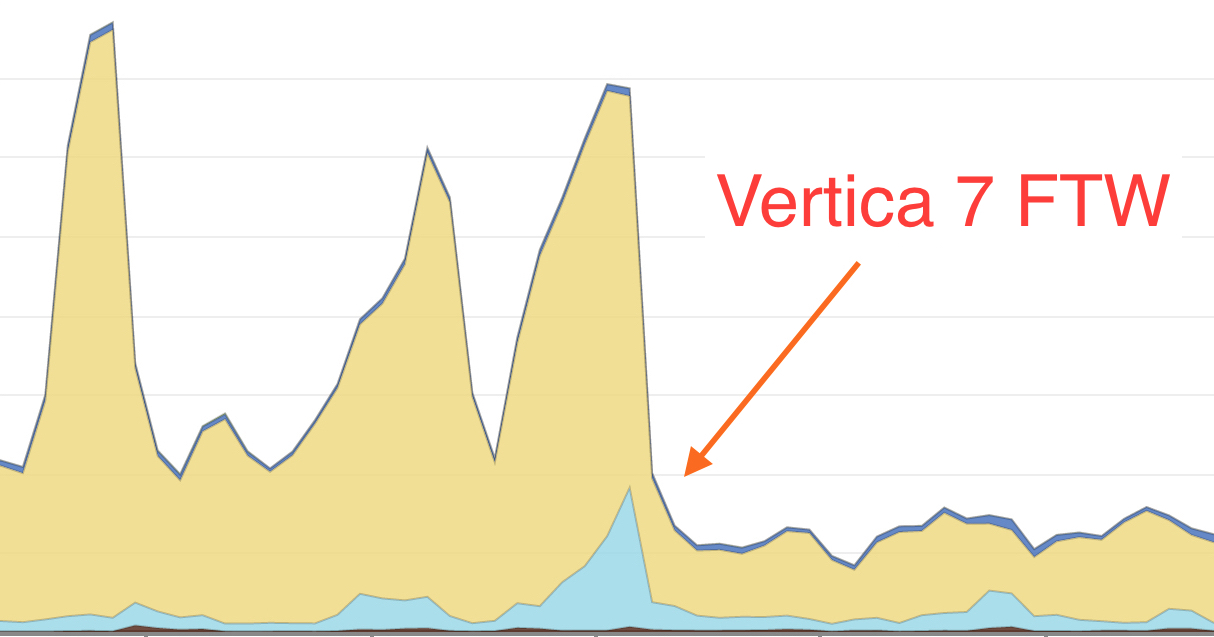
The majority of the difference we found in Vertica 7 that improved performance was that it helped lessen the magnitude of our performance spikes thus helped us avoid query traffic jams and thus produce faster results.
Lessons Learned
- Benchmark production traffic - there is no substitute.
- Every detail matters. - kernel versions, software versions, cores, network, i/o -- everything matters when optimizing a large-scale system like an MPP database running in the cloud.
- Amazon is amazing for iterating infrastructure Amazon’s EBS, EC2 and CloudFormation services made our iterations on this hardware so easy.
The next edge
We have been running on this configuration for a couple of months, and we are planning our next step up. Stay tuned for updates on how we iterate our Vertica infrastructure in future blog posts.
If you are looking to come help us find the next edge in our infrastructure. Please apply on our job page or message me directly (mklos@localytics.com)
Hero image of Mountain Goats courtesy of Flickr user annyuzza, CC-BY-NCND-2.0