We believe the highest performing engineering teams have a process to identify, triage, fix and learn from service degradations and downtime. At Localytics, we build highly available and scalable systems, and part of the key to our success is learning from failures. One way we foster a learning culture is through how we respond to pages we get about our services. We wanted to share our process for constantly improving.
1. Notify, Coordinate and Fix in Slack: #prod-issue
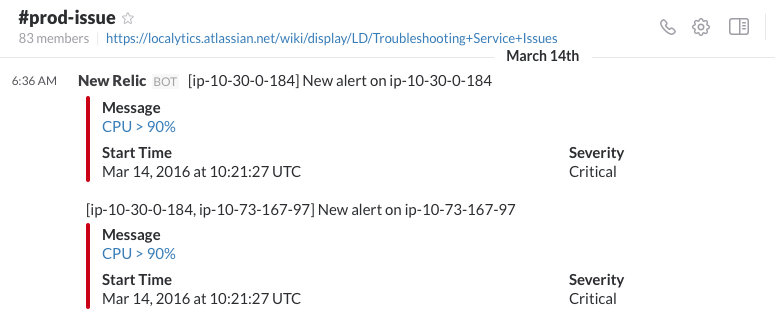
At Localytics, we're big believers in the power of chatops to scale our team. We use integrations with Slack to deploy code, run database migrations, and monitor dozens of services.
Pingdom, New Relic, AWS Cloudwatch, and coded circuit breaker patterns post to a #prod-issue channel in Slack. All of those systems separately notify the team through PagerDuty integration. An engineer's first response to receiving a PagerDuty is to open Slack and check #prod-issue for more details, rapidly speeding up triaging the issue. While you might get a page about a particular service being down, checking #prod-issue lets you see if there are, for example, larger service problems before digging any further.
Since it's a standard Slack chat room, engineers can coordinate the response and debug the issue in realtime, no matter where they are physically located. The chat history is a convenient record of what happened during the event and serves as the official record of the incident.
2. Debug and Start Postmortem in Slack: #postmorterm
After the initial crisis is over, our engineers move into the #postmortem Slack channel.
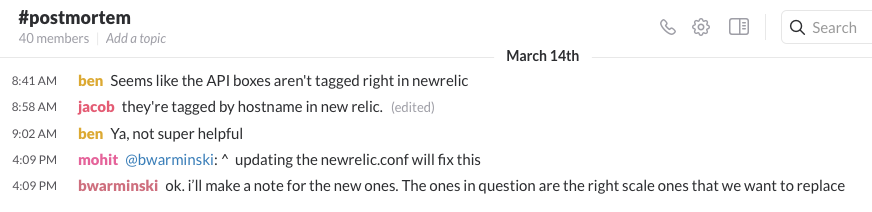
This is a place to hypothesize about what happened, challenge assumptions, and volunteer an Incident Leader to follow through. If the issue was a known risk that has now come to fruition, there's a good chance this conversation turns into a laundry list of ideas to fix the underlying issue. We often use the ideas generated here when we have the formal, blameless postmortem in Step 4.
3. Communicate to Company & Customers
A self-volunteered Incident Leader, usually the first person notified or "on the case", sends out an email to let the rest of the company know what happened. That distribution list goes to our Executive Team, Product leaders and Marketing department. It lets them decide whether to notify our customers proactively, or generate content to send to customers.
Here's the email template we use:
Subject: Issue Name, Date and Time
Hi everyone,
We experienced a production issue impacting [Service Name]. The issue began at [Time] on [Date] and ended on [Date].
Issue team:
- Engineering: @name
- Product Management: @name
- Product Marketing: @name
What is the issue and what caused it?
State what happened and why, in terms a general, non-technical audience can understand. Example: Database went down due to a bad query.
What is the impact to customers?
State the specific services that were impacted. Example: Push campaigns failed, attributions were not attributed, etc.
Which customers were affected?
Include a link to a Google Sheet containing the following fields: org name,org_id,app_id, andcampaign_idwhere applicable
What is the current status of the issue?
If the issue is resolved, state the fix and when it was deployed. If the issue is unresolved, give an approximate timeline for the fix.
Next steps
Product Marketing will follow up on this email thread with customer-facing messaging.
4. Hold a Blameless Postmortem
Within 24 business hours, the Incident Leader schedules and leads a Blameless Postmortem. This meeting can be anywhere from 30 minutes to several hours long. The point is to identify the processes, technologies and monitoring gaps that might have contributed to the issue.
The blameless concept is an important one. Postmortems should not be an exercise in identifying and disciplining specific engineers. Issues with services are rarely the fault of a single person. More likely, our internal processes and tools lead to the downtime, and the postmortem should focus on resolving those. This requires a belief that in a well-functioning team, people make rational decisions with the information they have, the resources available to them and the team support they receive. The only time spent identifying individual engineers is to bring them to the postmortem discussion.
Here are some examples of the different kinds of questions you ask in a blaming postmortem and a blameless one:
Example Incident 1: A database query brought down the database.
| "Blaming Postmortem" (Bad) | "Blameless Postmortem" (Good) |
|---|---|
| Why didn't [Engineer X] know enough SQL to understand that query would break the database? We need to shut off his/her access. | Did the peer review process not catch the query? Could this query be run on a Read Replica database instead of the primary? Does the team have enough education on Explain Plans to be informed about worrisome queries? |
Example Incident 2: Geographic coordinates are not processing correctly.
| "Blaming Postmortem" (Bad) | "Blameless Postmortem" (Good) |
|---|---|
| Which engineer forgot to write tests? | Does our release schedule discourage writing tests? Is there test coverage in any part of that code? Do we have an automated code coverage tool that can surface areas that need more tests? |
The Incident Leader's task is to fill out a Postmortem page on our internal Confluence wiki. Here's the template we use:
Date
Participants: @engineer1, @engineer2
Start every Postmortem stating the following
- This is a blameless Postmortem.
- Hindsight is 20/20 - we will not dwell on "could've" and "should've".
- Action items will have assignees. If the item is not going to be top priority leaving the meeting, don't make it a follow up item.
Incident Leader: @engineer
Description
[Short description of what the problem was]
Timeline
[2016-03-15] - @user does a thing
Contributing Factors
[What caused the problem? Use the 5 Whys if you'd like.]
How Did We Fix It?
[What did we do to stabilize our systems, either temporarily or permanently.]
Customer Impact
[How did this affect customers?]
Corrective Actions
[A list of TODOs with engineer names and expected dates]
This postmortem template has been modified for our process, from [GitHub user btm](https://gist.github.com/btm/7cb421f5fe7d1003083a).
We hope you find this process useful. We think it's been key to our success as we scale Localytics.
Photo Credit: Storm by javier ruiz77