Let’s continue to explore the idea that “every CPU cycle matters” when dealing with billions of records. In the last post, I introduced the impact of extra CPU cycles when you’re querying billions of records. This post will continue to explore areas of CPU cycle waste across layers and slices of technology.
Waste can occur when a computing system is spending cycles on tasks, which is not directly related to useful work (like running SQL query). Finding and eliminating this waste will free up CPU cycles and improve system performance.
Improve cluster efficiency through BIOS settings
The CPU itself is a very complicated component, but all complexity is hidden under the hood. Generally only hardware experts spend time on CPU configuration and tuning. Majority of people tend to think that tuning the CPU will not produce any significant performance gains.
We decided to challenge that assumption and looked deep into CPU tuning.
Image below shows the BIOS screen, which will allow you to make changes to CPU behavior. Some of those settings change internal CPU processing tremendously.

To experiment with CPU tuning we built a 3 node HP Vertica cluster and loaded it with several terabytes of data. Our goal was to research the impact of BIOS settings on the SQL queries execution time. We ran the same queries on the same dataset and on the same hardware, but with different sets of BIOS settings 3 times in a row.
Lower time means more efficient CPU usage and better query performance. Here are our findings (averaged, time in seconds):
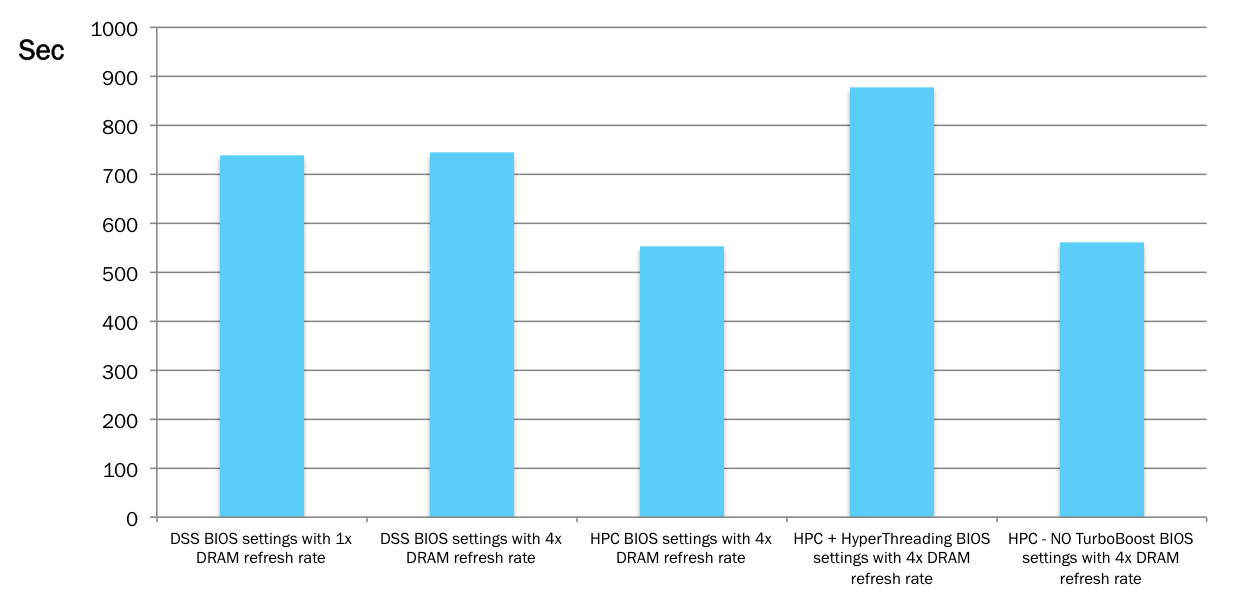
| Configuration description | Execution time (sec) |
|---|---|
| DSS BIOS settings with 1x DRAM refresh rate | 738 |
| DSS BIOS settings with 4x DRAM refresh rate | 745 |
| HPC BIOS settings with 4x DRAM refresh rate | 552 |
| HPC + HyperThreading BIOS settings with 4x DRAM refresh rate | 877 |
| HPC - NO TurboBoost BIOS settings with 4x DRAM refresh rate | 561 |
Fastest execution time we saw during benchmarking is 552 sec. Slowest time is 877 sec. The difference between the slowest and the fastest run is 40%. Those 40% represent a possible improvement as an outcome of CPU tuning effort.
Consider the CPU’s tuning effort. In our testing we clearly saw that disabling HyperThreading is greatly beneficial toward SQL performance for Vertica.
HyperThreading is the feature which makes one physical core appear as two cores to the operating system. This feature is beneficial for virtualized environments, but in Vertica workloads we saw a negative impact.
Keeping Vertica cluster processing optimal by staying in the same “technology slice”
Any database computing system will consist of 4 major layers, which sit on top of each other. Those major layers are:

Each layer depends on the layers below it. So when companies work on a new version of a product in any of the layers they use previously released products from the layers below. This dependency builds a pattern of releases in which technology in a higher layer is released later in time.
Following this diagram can give you a graphical illustration of this idea.
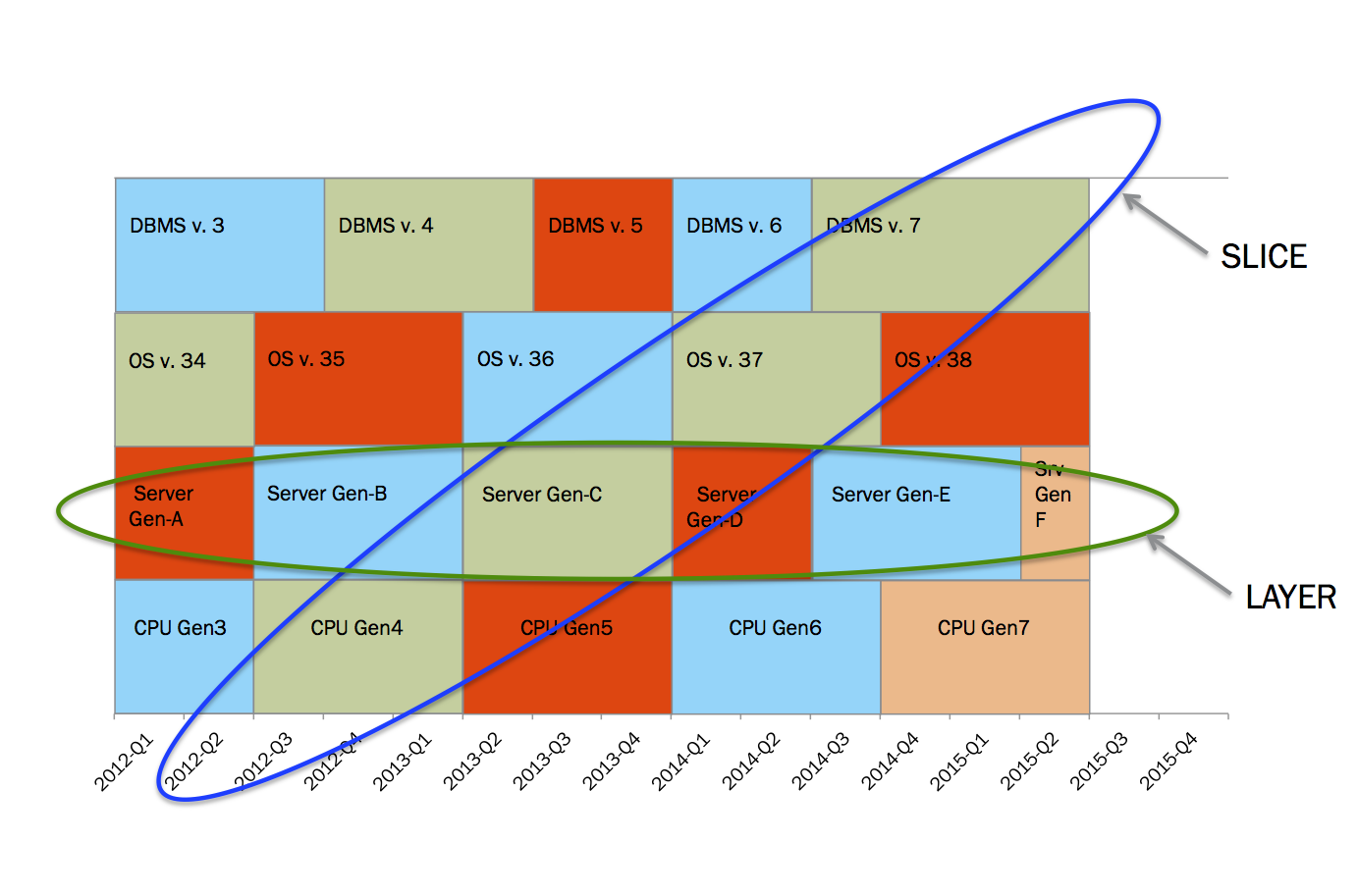
- It all starts with the creation of CPUs and chipsets.
- Once CPUs and chipsets are released, hardware manufacturers (HP, DELL, etc) start to work on the next generation of servers.
- When the new servers are ready they are taken by operational system companies and OS is tuned to take full advantage of the new hardware.
- When a new version of OS is released it gets in the hands of database companies and database engines are tuned to use all of the advantages of the new OS
- When database engines are certified to run on latest OS you have a full stack to build your system.
Take a look at the green check marks on the diagram below. Those check marks illustrate a good “technology slice”. Technologies included in a good “technology slice” are designed and tested to work together and provide you with the best possible performance.
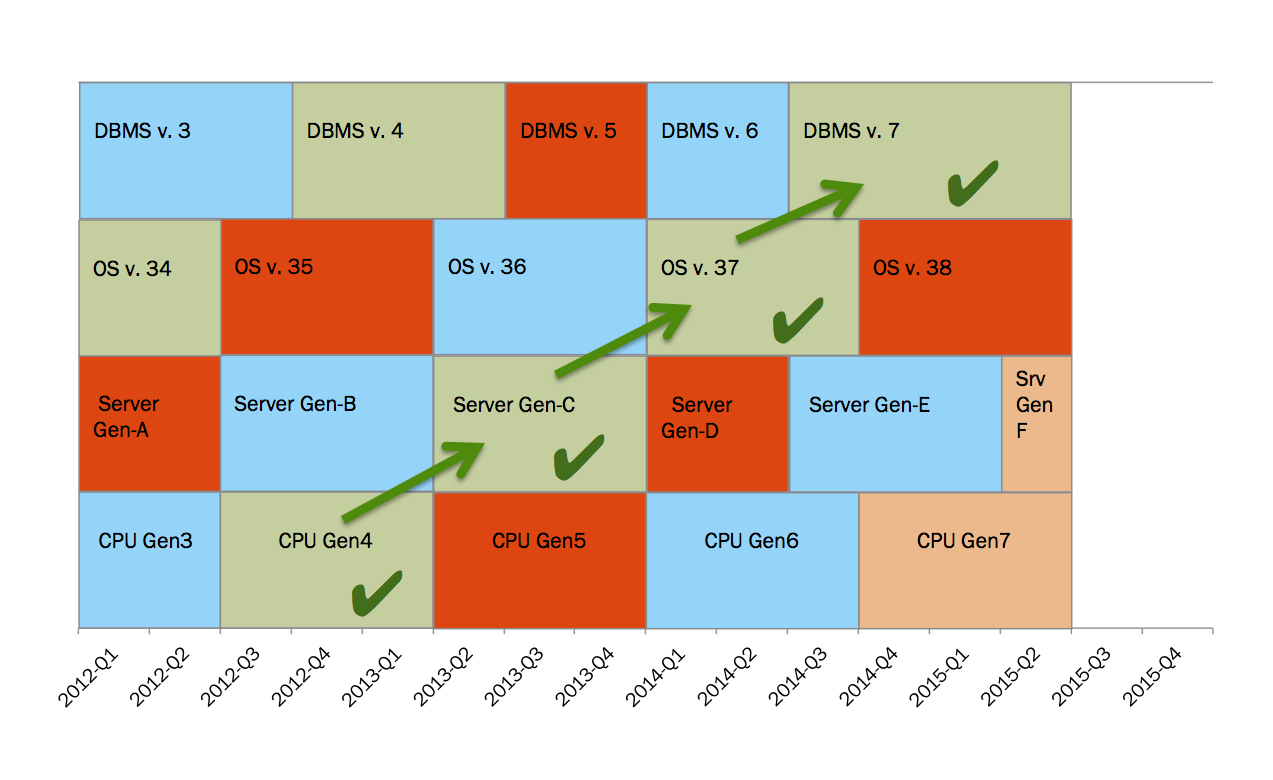
Common “TECHNOLOGY SLICE” Trap
Newer servers are most common solution in the situation when you need to get more performance out of the system. In most cases one will buy the latest and greatest servers, but will keep the database version from the existing setup.
Let’s say that our database was released 1 year ago and it was certified on OS, which was released 2 years ago. Once you take recently released servers and use a version of OS that is 2 years old (or older) you no longer have a good “technology slice”. You are trying to build your stack using technologies from different slices.
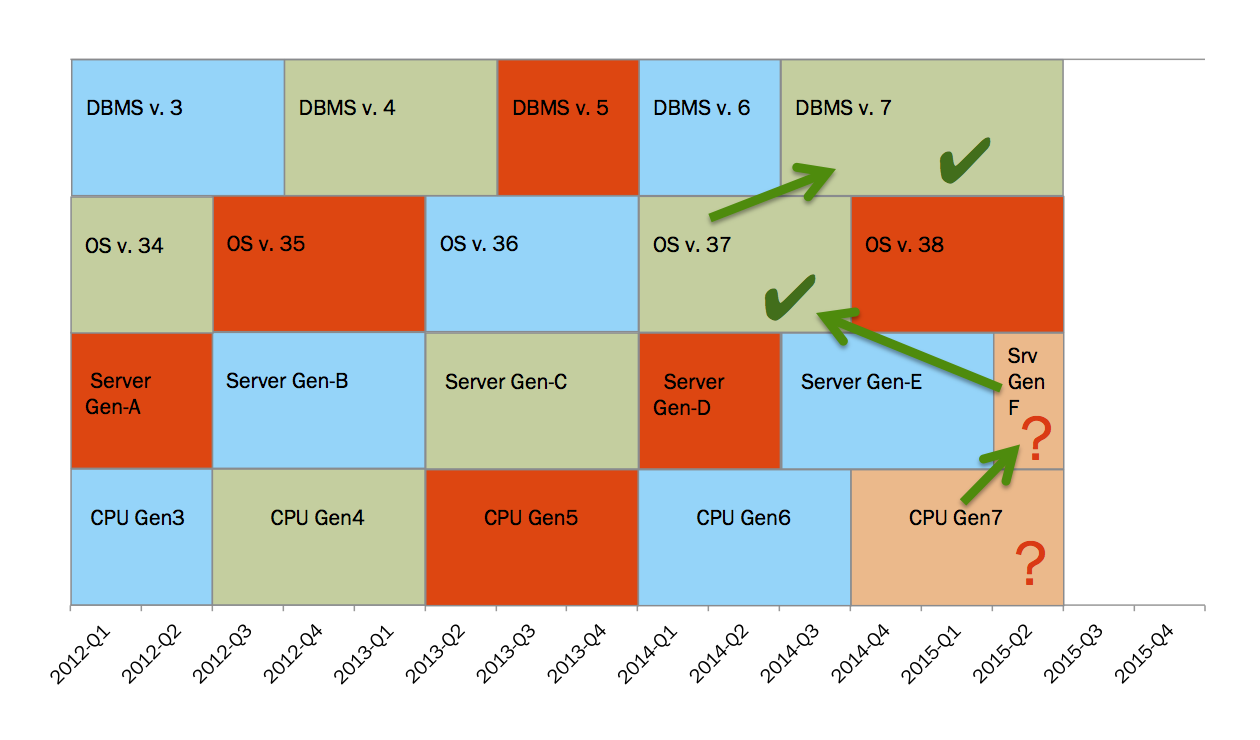
One of our research projects was about the replacement of older hardware with recently released hardware. In our experimental setup with recently released hardware we observed 2x performance degradation on SQL execution times. This was very unexpected. Further troubleshooting uncovered the fact that the system spent more CPU on system/kernel processing than on processing user/nice processing. In that case the older kernel was not able to work efficiently with the newer CPU architecture. The old kernel burned CPU cycles on managing higher core count instead of doing useful work. This issue was fixed when the OS vendor released kernel patches so that our environment was artificially pushed into the same “technology slice”.
Keep your system at its best possible performance levels by building your stack using technologies from one slice. When you are forced to use technologies from different slices make sure that the CPU cycles are spent on doing useful work.
Every CPU cycle matters !!! Can I call you a TRUE BELIEVER now?
if( you == "have comments" ) {
log("then comment");
} else if( you == "TRUE BELIEVER" ) {
log("reply to post 'EVERY CPU CYCLE MATTERS'");
} else {
log("Goodbye! and SHARE");
}
My name is Konstantine Krutiy, and I lead the Vertica team at Localytics. The clusters I am responsible for contain all of our analytics data (which amount to more than 1 trillion data points). In August of 2015 I presented at the HP Big Data Conference, and my session covered real-world methods for boosting query performance in Vertica. The talk was called "Extra performance out of thin air (full slide deck is here)".
> Photo Credit: Mark Freeth, "[IT makes you think](https://www.flickr.com/photos/freetheimage/15564627030)". Licensed under CC Attribution 2.0 Generic